Fairness in Practice: Auditing and Mitigating Bias in Your Machine Learning Models
28 August 2025
Author: Aadhavan Arkhash Saravanakumar, Machine Learning Intern
Co author: Varatharajah Vaseekaran, Senior Machine Learning Engineer

In 2018, a healthcare algorithm used across U.S. hospitals was found to prioritize white patients over Black patients for critical care, even when the Black patients were sicker. The model wasn’t explicitly told to discriminate, but it learned patterns from historical data that reflected deep-rooted societal inequities. This is not an isolated case. As Artificial Intelligence (AI) becomes embedded in decisions that affect people’s lives—from determining loan eligibility to predicting criminal recidivism—the risk of reinforcing or amplifying bias is no longer theoretical; it’s a real and urgent problem.
Bias in Machine Learning (ML) models isn’t just a technical oversight; it’s often a mirror of the unequal systems that generated the data. If left unaddressed, these biases can fuel discrimination, erode public trust, and lead to harmful real-world outcomes. In this blog, we delve into the practical aspects of achieving fairness in machine learning, examining the origins of bias, how to detect it, and what can be done to mitigate it effectively.
Understanding Bias
Bias in ML is not a singular entity but a spectrum of complications that can creep into your data and algorithms.
In simple terms, bias in Artificial Intelligence refers to the phenomenon where the model predictions are influenced by the characteristics of demographic factors, causing the privileged group(s) to be favored over the protected group(s). Privileged groups refer to the demographic groups that are usually given privileges by societal norms, whereas protected groups are the demographic groups that have fewer privileges.
In a high-level manner, bias can be categorized as follows:
-
- Historical bias: Even if data is perfectly measured and sampled, it may depict certain inequalities from the past. For example, employment records may disadvantage certain demographic groups due to decades of exclusionary practices.
- Representation bias: This arises when certain groups are underrepresented in training datasets. For example, facial recognition systems often perform poorly on darker-skinned individuals due to the imbalance in image datasets.
- Measurement/ Proxy Bias: This occurs when the features used to train models do not accurately capture the real-world attributes that they aim to represent. For example, a feature such as State Postal Codes being used in financial modelling may induce bias in terms of geographic location.
- Algorithmic Bias: Refers to bias introduced during model development when the optimization objectives prioritize overall performance, disregarding protected groups.
These biases tend to impact protected groups severely rather than the privileged groups.
Auditing for Fairness
Auditing a Machine Learning model for fairness involves evaluating how model predictions vary across different groups defined by demographic attributes such as race, gender, or age.
Several proven mathematical metrics exist to test for bias, with each being suited for different contexts:
- Demographic parity: Equal positive outcome rates across groups.
- Equal Opportunity: Equal true positive rates (e.g., equal likelihood of being correctly approved for a loan).
- Predictive Parity: Equal precision across groups.
- Disparate Impact Ratio: Proportion of favorable outcomes received by a protected group to that of a privileged group.
With time, several libraries and tools have been implemented to audit ML models for bias, such as:
- Performance metrics for each demographic group- recall, accuracy, and precision
- Fairness dashboards- IBM AI Fairness360, Fairlearn, and Google What-If
- Counterfactual testing- evaluating if changing a sensitive attribute while holding other features constant can alter the model prediction
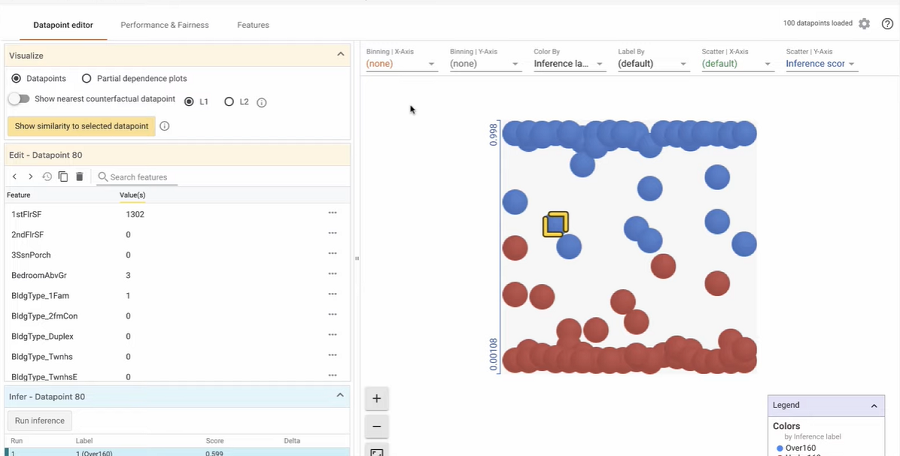
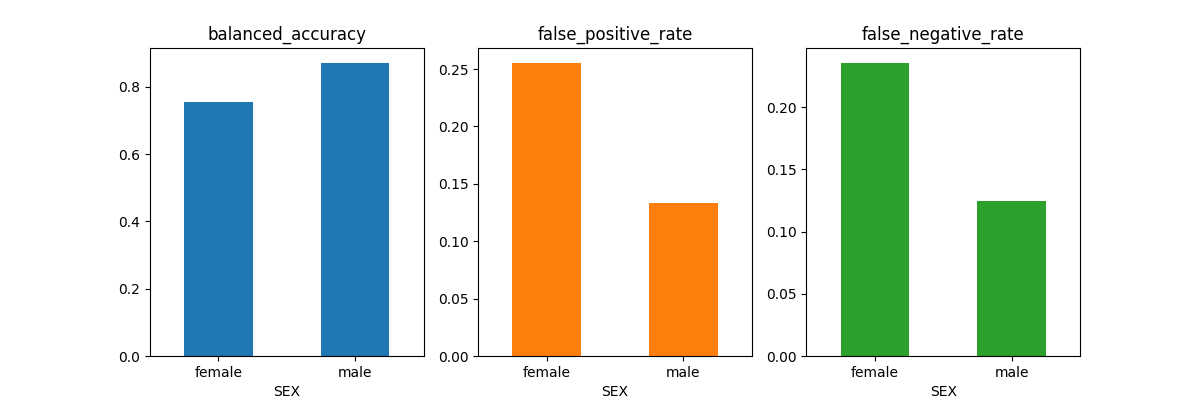
The above image shows how different metrics are evaluated based on a specific demographic feature (SEX in this example).
Mitigating Bias
Bias can be mitigated at multiple stages of the Machine Learning lifecycle:
Preprocessing
- Data Balancing: Use re-sampling techniques or synthetic generation to equally represent all demographic groups.
-
- Eg: Synthetic Minority Oversampling Technique
- Reweighing: Alter the weights of instances during training to offset imbalance.
- Fair feature engineering: Replace or remove biased features that may induce proxy bias.
In-processing
- Adversarial Debiasing: Train a model to make accurate predictions while preventing it from inferring sensitive demographic attributes.
- Fair Regularization: Define the loss function of the model such that penalties are given when fairness requirements are not met.
Post-processing
- Equalized Odds Adjustment: Modify predictions after training to equalize metrics like TPR and FPR across demographic groups.
Eg: In credit scoring, the accepted range for disparate impact ratio is 0.8 to 1.25 with an ideal value of 1.0.
- Reject Option Classification: In borderline prediction cases, favor the disadvantaged group to restore balance.
Each of these techniques comes with its trade-offs, which may sometimes require sacrificing a small percentage of overall accuracy to ensure no harm is done to protected groups, a trade-off well worth making.
Best Practices in Fair ML
Architecting a fair machine learning system is not a one-time effort but a recurrent process of monitoring and mitigation.
- Inclusive Data Collection: Ensure that the data collected is diverse across demographic groups. Discuss with domain experts to ensure the data reflects real-world diversity.
- Bias-aware Evaluation: Constantly monitor the performance of the models not only on accuracy but also on fairness metrics.
- Transparency and Explainability: Use interpretable models and explainability tools to understand how the model comes up with its predictions and possibly identify bias-inducing features.
- Human Oversight: Embed human-in-the-loop systems for high-stakes domains such as finance and healthcare, where ethics are of supreme value.
- Continuous Monitoring: Constantly monitor model behaviour post-deployment, as this may drift over time.
Challenges and Limitations
Despite the rapid growth of techniques and solutions for Fair Machine Learning, there remain strong challenges that occur due to social and technical traditions:
- Conflicting Definitions: There is no singular definition for fairness due to legal, cultural, and contextual differences.
- Trade-offs: Improving the fairness of a particular group may significantly affect another group or may even lead to tradeoffs between Fairness vs Accuracy.
- Data constraints: Sensitive attributes may not be always available due to privacy and legal concerns, thus eliminating the opportunity of conducting fairness tests.
- Over-correction: Overembellishing mitigation can lead to “reverse bias” or unfair advantage for certain groups.
Arguably, fairness is not a box to check but a series of ongoing, context-sensitive decisions.
The Road Ahead
Fairness and bias auditing is both a moral obligation and a technical challenge. It is the responsibility of developers to ensure that our models do not amplify social inequalities. With thoughtful auditing, deliberate mitigation and commitment to ethical best practices, we can build models that serve all users equitably.
While fairness poses potential challenges such as data limitation and tradeoffs, it remains an integral component of ethical AI development. From data collection, preprocessing and model training to deployment and monitoring, fairness must be integrated to depict social responsibility and interdisciplinary awareness.
Insights for this article were drawn from research and thought leadership by PBS NOVA, SAP, Fairlearn, IBM’s AIF360, MathWorks, and academic publications on AI fairness.
